OmniMMI: A Comprehensive Multi-modal Interaction Benchmark in Streaming Video Contexts
CVPR 2025
Multimodal Multiplexing Modeling
Proactive Generation
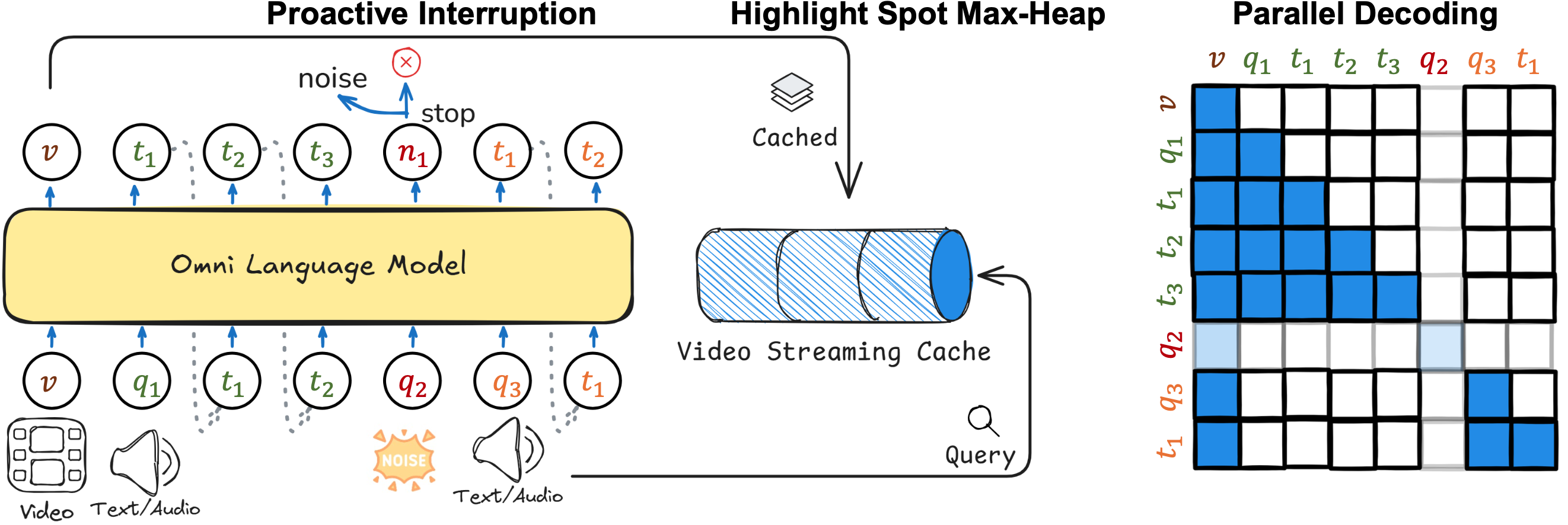
We derive an attention-based inference method, highlight spot, to enable videoLLM real-time proactive generation without additional training.
- For each in-coming frame \(v\), we pre-compute \(K=W_kv\) and \(Vj=W_Vv\) vectors to form a KV cache. The attention scores between the query \(q\) and the frames are calculated \(w.r.t.\) the KV cache, \(i.e.\), \(s = \text{softmax}\left(\frac{qK^{\rm T}}{\sqrt{d_k}}\right)\), with their mean and variance computed as \(\mu,\sigma\)
- Indices of frames whose attention scores exceed the Gaussian average \(\mu + \alpha \times \sigma\) are stored in a max heap, where \(\alpha\) is a Gaussian factor.
- The peak index from max-heap is extracted. If a frame index has a higher occurrence frequency than a predetermined threshold, it is designated as an "alert", triggering a response generation.
Proactive Generation Demo
Query: Please notify me when there is a mixer.
Proative Turn Taking
To equip the model with real-time interactive modeling capabilities, we propose incorporating interruption detection and parallel decoding.
- Start Detection.In this process, we calculate the probability of the "<bos>" token as a reference point. Drawing inspiration from medusa, we utilize the reciprocal of perplexity as the threshold for identifying this special token.
\[ p(x_{n+k} \mid x_1, x_2, \ldots, x_{n+k-1}) > \beta \cdot \exp \left( -S\left( p(\cdot \mid x_1, x_2, \ldots, x_{n+k-1}) \right) \right) \]
, where \(\beta\) is a scaling factor, \(S(\cdot)\) is the entropy function. The threshold for noise detection is dependent on the perplexity of the model. When there is a larger perplexity, the threshold is reduced, indicating the query is more like a noise that does not need a response. - End Detection. Knowing when to stop is a critical feature of an interactive system, which we consider essential for developing a duplex system. Similar to noise detection, when presented with a new query, we assess whether to halt the generation process by calculating the probability of the "<eos>" token in a single forward pass. This decision is made using the same threshold employed in start detection.
- Parallel Decoding. when the model is generating new tokens and a new input query arises, the model decodes the next token alongside the original token using a combination of causal masks, prefix masks, and block masks. Specifically, the causal mask is applied for the language model, the prefix mask pertains to the video context, and the block mask is designed to separate the decoding procedures of the input and output in parallel.
Proactive Turn-taking Demo
Task: normal query \(V.S.\) noise query.
Citation
@misc{omnimmi,
title={OmniMMI: A Comprehensive Multi-modal Interaction Benchmark in Streaming Video Contexts},
author={Wang, Yuxuan and Wang, Yueqian and Chen, Bo and Wu, Tong and Zhao, Dongyan and Zheng, Zilong},
publisher={CVPR},
year={2025}
}